git の使い方メモ [Git]
mybranch と言う名のブランチ作成
以下の一行でも同じ
mybrancyh をリモートに push
mybranch を master にマージ
変更取り消し
ブランチを削除
git branch mybranch git checkout mybranch
以下の一行でも同じ
git checkout -b mybranch
mybrancyh をリモートに push
git commit -a -m "implemented blah blah" git push origin mybranch
mybranch を master にマージ
git checkout master git merge --no-ff mybranch
変更取り消し
git reset --hard HEAD
ブランチを削除
git branch --delete mybranch git push --delete origin mybranch
boost1.59 を VS2013 でビルド [C++]
マルチスレッドDLL とかの設定がほかの lib と合わずエラーがでるので、boost を
ビルドしなおしました。
毎回面倒なので全種類作っておこうと思い、
- x86/x64
- static lib or dll
- static runtime link or dll runtime link
で 8 種類(debug/releaseあわせると16種類)いるのか!と思いましたが、
dll の boost に static の runtime は link できないみたい。
確かに別の dll や本体アプリで違う種類の runtime がリンクされてたら
インスタンスが2つ要るのでおかしなことになる。
リリース/デバッグビルドは "variant=debug,release"と書けば両方ビルドされるみたい。
あと "link=static,shared" もいけるとどこかにあったけど未確認。
使ったVSは2013 , boost1.59 です。
ビルドしなおしました。
毎回面倒なので全種類作っておこうと思い、
- x86/x64
- static lib or dll
- static runtime link or dll runtime link
で 8 種類(debug/releaseあわせると16種類)いるのか!と思いましたが、
dll の boost に static の runtime は link できないみたい。
確かに別の dll や本体アプリで違う種類の runtime がリンクされてたら
インスタンスが2つ要るのでおかしなことになる。
リリース/デバッグビルドは "variant=debug,release"と書けば両方ビルドされるみたい。
あと "link=static,shared" もいけるとどこかにあったけど未確認。
使ったVSは2013 , boost1.59 です。
rem x86, static lib, static rt(MT/MTd) : xxx-vc120-mt-x_xx.lib, xxx-vc120-mt-gd-x_xx.lib
b2.exe --toolset=msvc-12.0 variant=debug,release link=static threading=multi runtime-link=static --stagedir=stage\x86\vc12\static\mt --without-python --without-mpi --build-type=complete address-model=32
rem x86, static lib, dynamic rt(MD/MDd) : xxxx-vc120-mt-x_xx.lib, xxxx-vc120-mt-gd-x_xx.lib
b2.exe --toolset=msvc-12.0 variant=debug,release link=static threading=multi runtime-link=shared --stagedir=stage\x86\vc12\static\md --without-python --without-mpi --build-type=complete address-model=32
rem x86, dynamic lib, static rt(MT/MTd) : この組み合わせはNG
b2.exe --toolset=msvc-12.0 variant=debug,release link=shared threading=multi runtime-link=static --stagedir=stage\x86\vc12\dynamic\mt --without-python --without-mpi --build-type=complete address-model=32
rem x86, dynamic lib, dynamic rt(MD/MDd) : xxx-vc120-mt-x_xx.{dll,lib}, xxx-vc120-mt-gd-x_xx.{dll,lib}
b2.exe --toolset=msvc-12.0 variant=debug,release link=shared threading=multi runtime-link=shared --stagedir=stage\x86\vc12\dynamic\md --without-python --without-mpi --build-type=complete address-model=32
rem x64, static lib, static rt(MT/MTd)
b2.exe --toolset=msvc-12.0 variant=debug,release link=static threading=multi runtime-link=static --stagedir=stage\x64\vc12\static\mt --without-python --without-mpi --build-type=complete address-model=64
rem x64, static lib, dynamic rt(MD/MDd)
b2.exe --toolset=msvc-12.0 variant=debug,release link=static threading=multi runtime-link=shared --stagedir=stage\x64\vc12\static\md --without-python --without-mpi --build-type=complete address-model=64
rem x64, dynamic lib, static rt(MT/MTd) : この組み合わせは NG
b2.exe --toolset=msvc-12.0 variant=debug,release link=shared threading=multi runtime-link=static --stagedir=stage\x64\vc12\dynamic\mt --without-python --without-mpi --build-type=complete address-model=64
rem x64, dynamic lib, dynamic rt(MD/MDd)
b2.exe --toolset=msvc-12.0 variant=debug,release link=shared threading=multi runtime-link=shared --stagedir=stage\x64\vc12\dynamic\md --without-python --without-mpi --build-type=complete address-model=64
「A SMARTERWAY TO FIND PITCH」でピッチ検出 [Math]
音声の波形からピッチを検出するアルゴリズム にピッチ検出の論文が
解説されていて、 scilab でやってみました。
Normalized Square Difference なるものを計算して、
次のアルゴリズムで音程を決定するとのこと。
1.極大値をリストアップ
2.その中から傾きが正で0を跨ぐ部分から、負で0を跨ぐ部分の間で最大のものに絞る。
ただし、傾き生で0を跨ぐが、途中で切れているものも候補に入れておく
3.最大値を nmax として、k * nmax のもので、最初にでてくるもの(周波数が小さいもの)
を選ぶ。k は 0.8~1.0 で要調節。
440Hzの正弦波のNormalized Square Difference を描いたものがこちら。
計算あってるのか?-1~1 になっているからたぶんあってる。
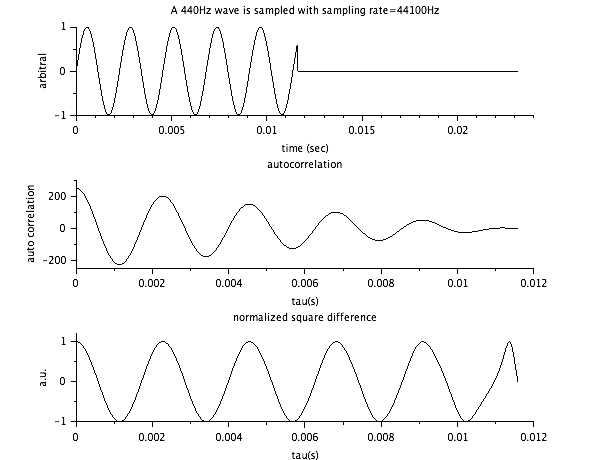
上記のアルゴリズムを適用すると、たしかに1/440=0.00227 が取れそうな感じだ。
もっといろんな音で確かめたい。
使った scilab コードはこちら。
解説されていて、 scilab でやってみました。
Normalized Square Difference なるものを計算して、
次のアルゴリズムで音程を決定するとのこと。
1.極大値をリストアップ
2.その中から傾きが正で0を跨ぐ部分から、負で0を跨ぐ部分の間で最大のものに絞る。
ただし、傾き生で0を跨ぐが、途中で切れているものも候補に入れておく
3.最大値を nmax として、k * nmax のもので、最初にでてくるもの(周波数が小さいもの)
を選ぶ。k は 0.8~1.0 で要調節。
440Hzの正弦波のNormalized Square Difference を描いたものがこちら。
計算あってるのか?-1~1 になっているからたぶんあってる。
上記のアルゴリズムを適用すると、たしかに1/440=0.00227 が取れそうな感じだ。
もっといろんな音で確かめたい。
使った scilab コードはこちら。
scilab で自己相関関数 [Math]
信号 x = {...} があったらその自己相関関数を求めるには、
ざっくりと以下のようになる。
パワースペクトルは元信号をフーリエ変換して求める。
P=|F(x)|^2
自己相関関数のフーリエ変換でもパワースペクトルが求まる
(ウィーナー=ヒンチンの定理と言うそうな)。
P=F(r)/N
なのでパワースペクトルをフーリエ逆変換すると自己相関関数が得られる。
自己相関をは直接求めると計算コストがかかるので、x を fft して P を
求め、それをフーリエ逆変換して求めるのが一般的。
みたいなことが、教科書とかに書いてある。あ、そうなんですか…と。
ピンとこないので scilab で見てみました。
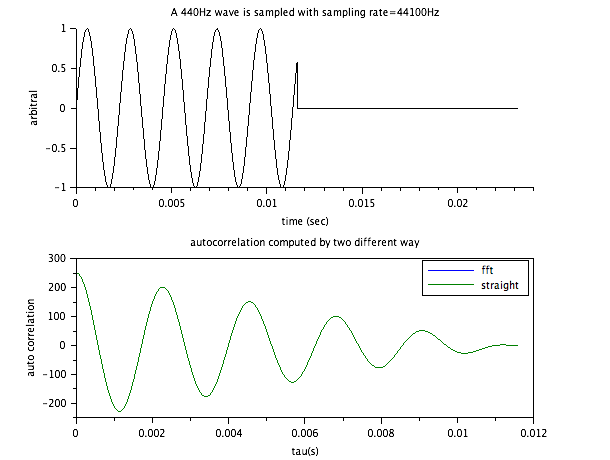
fft+ifft で求めた自己相関関数と、ごりごり計算した自己相関関数が
ぴったりと重なりました。fft+ifft の方はパワースペクトルと同じく
真ん中で対象になっているので、データを半分にして表示しました。
使った scilab スクリプト
ざっくりと以下のようになる。
パワースペクトルは元信号をフーリエ変換して求める。
P=|F(x)|^2
自己相関関数のフーリエ変換でもパワースペクトルが求まる
(ウィーナー=ヒンチンの定理と言うそうな)。
P=F(r)/N
なのでパワースペクトルをフーリエ逆変換すると自己相関関数が得られる。
自己相関をは直接求めると計算コストがかかるので、x を fft して P を
求め、それをフーリエ逆変換して求めるのが一般的。
みたいなことが、教科書とかに書いてある。あ、そうなんですか…と。
ピンとこないので scilab で見てみました。
fft+ifft で求めた自己相関関数と、ごりごり計算した自己相関関数が
ぴったりと重なりました。fft+ifft の方はパワースペクトルと同じく
真ん中で対象になっているので、データを半分にして表示しました。
使った scilab スクリプト
funcprot(0);
clear all;
//////////////////////////////////////////////////////////////////////
// parameters
//////////////////////////////////////////////////////////////////////
sampleNum = 1024; // sample number
sampleFreq = 44100; // sampling frequency
waveFreq = 440; // wave frequency
//////////////////////////////////////////////////////////////////////
// main
//////////////////////////////////////////////////////////////////////
// create time-axis
ts = [0:sampleNum-1] * 1/sampleFreq;
// create sin wave
x=sin(2 * %pi * waveFreq * ts);
x(sampleNum/2+1:sampleNum)=zeros(1,sampleNum/2);
// create freq-axis
fs = [0:sampleNum-1] * sampleFreq/sampleNum;
// data number for fft
N = sampleNum;
// fft
f_fft = fft(x);
power = f_fft.*conj(f_fft);
// correlation by fft
r=ifft(power);
taus=[0:N-1] * 1/sampleFreq;
// correlation by hand
M=N/2;
r2=zeros(1,M);
taus2=[0:M-1] * 1/sampleFreq;
for m=1:M+1
for n=1:M-m+1
r2(m)=r2(m)+x(n)*x(n+m-1);
end;
end;
subplot(211);
plot2d(ts,x);
title = sprintf("A %dHz wave is sampled with sampling rate=%dHz",waveFreq,sampleFreq);
xtitle(title,"time (sec)","arbitral");
subplot(212);
plot(taus(1:M),r(1:M),taus2,r2);
xtitle("autocorrelation computed by two different way", "tau(s)", "auto correlation");
legend(["fft" "straight"], 1, "ur");
ピッチ検出に必要なバッファサイズ [Math]
ピアノの最低音の周波数は27.5Hzとのこと。
( http://d.hatena.ne.jp/session_oyaji/20070520/1179666560 )
これの周期を図れるくらいバッファに貯めると
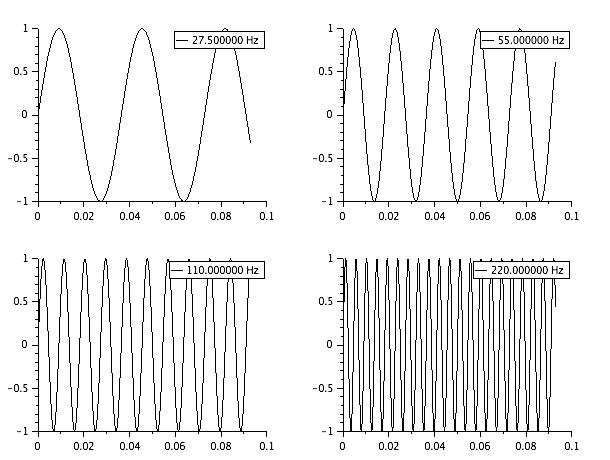
どんな感じになるのかを scilab で見てみました。
44.1KHz で 4096 個サンプリングすると、
275Hz, 55Hz, 110Hz,... はこんな感じになります。
低い周波数を対象にすると結構長い事サンプリングが必要だなーと。
サンプリング周波数を下げれば良いですが、同時に高い周波数も
対象にしたいですし。悩ましい。
かといってまだ何も実装していないので、4096 このサンプリングが
どれほどの負荷なのか知りませんけど。時間にして 0.1 秒くらいは
サンプリングしないとダメなんですね。
使った scilab のコードは以下。
( http://d.hatena.ne.jp/session_oyaji/20070520/1179666560 )
これの周期を図れるくらいバッファに貯めると
どんな感じになるのかを scilab で見てみました。
44.1KHz で 4096 個サンプリングすると、
275Hz, 55Hz, 110Hz,... はこんな感じになります。
低い周波数を対象にすると結構長い事サンプリングが必要だなーと。
サンプリング周波数を下げれば良いですが、同時に高い周波数も
対象にしたいですし。悩ましい。
かといってまだ何も実装していないので、4096 このサンプリングが
どれほどの負荷なのか知りませんけど。時間にして 0.1 秒くらいは
サンプリングしないとダメなんですね。
使った scilab のコードは以下。
funcprot(0);
clear all;
//////////////////////////////////////////////////////////////////////
// parameters
//////////////////////////////////////////////////////////////////////
sampleNum = 4096; // sample number
sampleFreq = 44100; // sampling frequency
baseWaveFreq = 27.5;// base wave frequency
//////////////////////////////////////////////////////////////////////
// main
//////////////////////////////////////////////////////////////////////
// create time-axis
ts = [0:sampleNum-1] * 1/sampleFreq;
// create sin wave of frequency
// 27.5, 55, 110, 220, 440, 880, 1760, 3520 Hz
powNum = 4;
pows=[0:powNum-1]';
fs=baseWaveFreq*(2^pows);
waves = sin(2 * %pi * fs * ts);
// plot
for i=1:powNum,
subplot(int(powNum/2)*100+20+i)
plot2d(ts,waves(i,:));
legendtext = sprintf("%f Hz",fs(i));
legends(legendtext,1,"ur");
end
scilab で fft [Math]
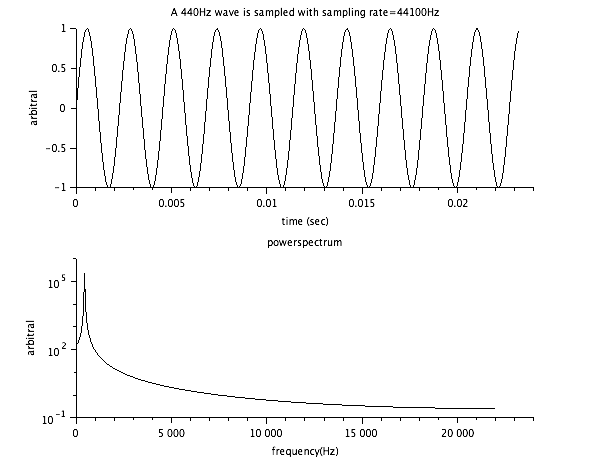
前回の正弦波を fft してみた。
fft の分解能は サンプリング周波数/サンプルの数 だそうで、
今回は 44100 Hz/1024=約43.1Hz
なので、 430 Hz のデータが最大なので、そこから + 43.1 した
430 〜 473 Hz の範囲が最大なんじゃないかと。であれば 440Hz
はこの範囲なのであってるなと。
scilab スクリプトはこんな感じ。
fft の分解能は サンプリング周波数/サンプルの数 だそうで、
今回は 44100 Hz/1024=約43.1Hz
なので、 430 Hz のデータが最大なので、そこから + 43.1 した
430 〜 473 Hz の範囲が最大なんじゃないかと。であれば 440Hz
はこの範囲なのであってるなと。
scilab スクリプトはこんな感じ。
funcprot(0);
clear all;
//////////////////////////////////////////////////////////////////////
// parameters
//////////////////////////////////////////////////////////////////////
sampleNum = 1024; // sample number
sampleFreq = 44100; // sampling frequency
waveFreq = 440; // wave frequency
//////////////////////////////////////////////////////////////////////
// main
//////////////////////////////////////////////////////////////////////
// create time-axis
ts = [0:sampleNum] * 1/sampleFreq;
// create sin wave
f=sin(2 * %pi * waveFreq * ts);
// data number of data for fft
N = sampleNum/2;
// create freq-axis
fs = [0:sampleNum] * sampleFreq/sampleNum;
// fft
f_fft = fft(f);
power = f_fft.*conj(f_fft);
subplot(211);
plot2d(ts,f);
title = sprintf("A %dHz wave is sampled with sampling rate=%dHz",waveFreq,sampleFreq);
xtitle(title,"time (sec)","arbitral");
subplot(212);
plot2d("nl",fs(1:N),power(1:N));
xtitle("powerspectrum", "frequency(Hz)", "arbitral");
[maxPower,maxIndex] = max(abs(power(1:N)));
maxFreq=fs(maxIndex);
printf("max frequency range=%f~%f\n",maxFreq, maxFreq + sampleFreq/sampleNum);
scilab で正弦波を描く [Math]
scilab で音声の解析とかしたい。
久しぶりなのでリハビリを兼ねて正弦波を描く練習。
440Hz(ラの音)を44.1KHzでサンプリングしたものを1024個取り出して表示。
周期は 1/440=0.0023 だからたぶん合ってる。
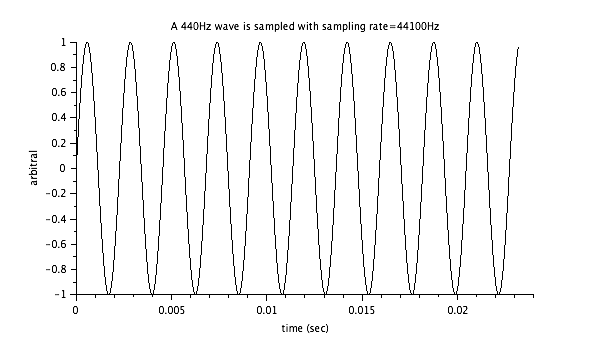
scilab のスクリプトはこんな感じ。
久しぶりなのでリハビリを兼ねて正弦波を描く練習。
440Hz(ラの音)を44.1KHzでサンプリングしたものを1024個取り出して表示。
周期は 1/440=0.0023 だからたぶん合ってる。
scilab のスクリプトはこんな感じ。
funcprot(0);
clear all;
//////////////////////////////////////////////////////////////////////
// parameters
//////////////////////////////////////////////////////////////////////
sampleNum = 1024; // sample number
sampleFreq = 44100; // sampling frequency
waveFreq = 440; // wave frequency
//////////////////////////////////////////////////////////////////////
// main
//////////////////////////////////////////////////////////////////////
ts = [0:sampleNum-1] * 1/sampleFreq;
f=sin(2 * %pi * waveFreq * ts);
plot2d(ts,f);
title = sprintf("A %dHz wave is sampled with sampling rate=%dHz",waveFreq,sampleFreq);
xtitle(title,"time (sec)","arbitral");
hstファイルをcsvに変換 [C++]
別にFXをやっている訳ではないんですが、いやちょっとはやってみたいとも思いますけど、そもそも元手が(10万とか)ないんで無理なのが悲しいところ。でもちょっと世界をのぞいてみたいと思いまして、為替相場の動きを観察しようと思います。
そのためにはまず過去のデータが必要です。2005年から1分ごとのデータが、FXDD という証券会社のメタトレーダーのヒストリカルデータというところからダウンロードできました。
さて、このデータ。メタトレーダー4というFX取引用のアプリのフォーマットのようです。
フォーマットの中身はMT4を使ってFXに解説されていました。
探せばごろごろあるのでしょうが、向学のために csv に変換するプログラムを書いてみました。本当は C# でサクッと行きたかったのですが、諸事情により VisualStudio をインストールしていないので、 xcode で c++ で書きました。
ソースコードは GitHub からダウンロードできます。
#pragma pack でバイトアラインを無効にして、構造体に一気にデータを読み込んでいます。
これってバイトオーダーが違う処理系だったら大丈夫なのでしょうか。
そしてフォーマットにある time_t はなんと 32bit time_t のことの様なので、
uint32_t に置き換えて構造体に取り込んで、使うときに time_t にキャストしています。
次のように実行して USDJPY.hst を csv に変換して output.csv に書き出します。
できたファイルの内容はこんな感じ。
さてこれを使ってどうするか。
そのためにはまず過去のデータが必要です。2005年から1分ごとのデータが、FXDD という証券会社のメタトレーダーのヒストリカルデータというところからダウンロードできました。
さて、このデータ。メタトレーダー4というFX取引用のアプリのフォーマットのようです。
フォーマットの中身はMT4を使ってFXに解説されていました。
探せばごろごろあるのでしょうが、向学のために csv に変換するプログラムを書いてみました。本当は C# でサクッと行きたかったのですが、諸事情により VisualStudio をインストールしていないので、 xcode で c++ で書きました。
ソースコードは GitHub からダウンロードできます。
#include#include #include #include using namespace std; typedef struct _HistoryHeader { uint32_t version; char copyright[64]; char symbol[12]; int32_t period; int32_t digits; uint32_t timesign; uint32_t last_sync; uint32_t reserved[13]; } HistoryHeader; #pragma pack(push,1) typedef struct _RateInfo { uint32_t ctm; double open; double low; double high; double close; double vol; } RateInfo; #pragma pack(pop) void printHistoryHeader(const HistoryHeader& header) { cout << "version : " << header.version << endl; cout << "copyright : " << header.copyright << endl; cout << "symbol : " << header.symbol << endl; cout << "period : " << header.period << endl; cout << "digits : " << header.period << endl; time_t tmp = header.timesign; cout << "timesign : " << put_time(localtime(&tmp), "%F %T") << endl; tmp = header.last_sync; cout << "last_sync : " << put_time(localtime(&tmp), "%F %T") << endl; } void printRate(const RateInfo& rate, ostream& ost) { time_t tmp = rate.ctm; ost << put_time(std::localtime(&tmp), "%F %T"); ost << "," << rate.open; ost << "," << rate.low; ost << "," << rate.high; ost << "," << rate.close; ost << "," << rate.vol << endl; } int main(int argc, const char * argv[]) { if(argc < 2) { cout << "need to give hst file and output file" << endl; cout << "ex) hstconverter [hst file] [output file]" << endl; return 1; } ifstream ifs; ifs.open(argv[1], ios::in | ios::binary); if(!ifs) { cout << "file open error" << endl; return 1; } HistoryHeader header; ifs.read((char*)&header, sizeof(header)); if(ifs.bad()) { cout << "file read error" << endl; return 1; } printHistoryHeader(header); ofstream ofs; ofs.open(argv[2], ios::out | ios::trunc); if(!ofs.is_open()) { cout << "failed to create a file : " << argv[2] << endl; return 1; } RateInfo rate; while(!ifs.eof()) { ifs.read((char*)&rate, 44); if(ifs.bad()) { cout << "file read error" << endl; return 1; } printRate(rate, ofs); } cout << "done" << endl; return 0; }
#pragma pack でバイトアラインを無効にして、構造体に一気にデータを読み込んでいます。
これってバイトオーダーが違う処理系だったら大丈夫なのでしょうか。
そしてフォーマットにある time_t はなんと 32bit time_t のことの様なので、
uint32_t に置き換えて構造体に取り込んで、使うときに time_t にキャストしています。
次のように実行して USDJPY.hst を csv に変換して output.csv に書き出します。
hstconverter USDJPY.hst output.csv
できたファイルの内容はこんな感じ。
2005-01-10 11:31:00,104.79,104.79,104.79,104.79,5 2005-01-10 11:32:00,104.79,104.78,104.79,104.78,6 2005-01-10 11:33:00,104.78,104.77,104.78,104.77,5 ... 2014-08-09 07:59:00,102.063,102.06,102.067,102.064,34 2014-08-09 07:59:00,102.063,102.06,102.067,102.064,34
さてこれを使ってどうするか。
二項分布から拡散方程式 [Math]
二項分布では n ステップ後に位置 x にいる確率は p(x,n) で表しました。
この確率から差分方程式を作って拡散方程式が導かれます。せっかく p(x,n)
を前回計算したので、拡散方程式も見てみないとモッタイナイのでここに
書いておきます。なお、内容は検索で出てきた立命館大学の講義資料の
まんまです。
今回 x は変数変換後の変数として使うので、変換前は m と書いておきます。
なので、n ステップ後に位置 m にいる確率を p(m,n) と今回は表記します。
ステップ n+1 で m にいる確率 p(m,n+1)は以下のようになる。
=\frac{1}{2}p(m%2B1,n)%2B\frac{1}{2}p(m-1,n))
(ステップ n で m-1 にいる確率)*(右に移動する確率)と
(ステップ n で m+1 にいる確率)*(左に移動する確率の和。
これを変形して(こんな変形思いつかないけど、賢い人は変形できるんでしょうねぇ)
-p(m,n)=\frac{1}{2}\left\{p(m%2B1,n)%2Bp(m-1,n)-2p(m,n)\right\})
変数変換で極限をとって連続にする。



連続版の確率密度分布を f(x,t) とすると、区間 Δx の確率は次のように表せる。
=f(x,t)\Delta{x})
差分方程式を f(x,t) で表すと
=\frac{1}{2}\left\{ f(x%2B\Delta{x},t)%2B f(x-\Delta{x},t)-2f(x,t)\right\})
微分の形に変形して
-f(x,t)}{\Delta t}=\frac{{\Delta{x}}^2}{2\Delta{t}} \frac{ \frac{f(x%2B\Delta{x},t)-f(x,t)}{\Delta x} %2B \frac{f(x,t)-f(x-\Delta{x},t)}{\Delta{x}}}{\Delta x})
こんな変形絶対できないんですけど。まぁ、天才アインシュタインが
考えてノーベル賞を取った理論だそうなので、できなくて当然。
 を保ったまま
を保ったまま
そんなこと言われても、ああそうですかとしか。
最終的に得たのが次の式で、Dを拡散係数と呼ぶ。
}{\partial t}=D\frac{\partial^2 f(x,t)}{\partial x^2})
元の講義ノートから変数の文字を変えたりして結局見にくくなった感が。。。
まぁこれを書いてわかった気になるのがひとつの目的なので。
この確率から差分方程式を作って拡散方程式が導かれます。せっかく p(x,n)
を前回計算したので、拡散方程式も見てみないとモッタイナイのでここに
書いておきます。なお、内容は検索で出てきた立命館大学の講義資料の
まんまです。
今回 x は変数変換後の変数として使うので、変換前は m と書いておきます。
なので、n ステップ後に位置 m にいる確率を p(m,n) と今回は表記します。
ステップ n+1 で m にいる確率 p(m,n+1)は以下のようになる。
(ステップ n で m-1 にいる確率)*(右に移動する確率)と
(ステップ n で m+1 にいる確率)*(左に移動する確率の和。
これを変形して(こんな変形思いつかないけど、賢い人は変形できるんでしょうねぇ)
変数変換で極限をとって連続にする。
連続版の確率密度分布を f(x,t) とすると、区間 Δx の確率は次のように表せる。
差分方程式を f(x,t) で表すと
微分の形に変形して
こんな変形絶対できないんですけど。まぁ、天才アインシュタインが
考えてノーベル賞を取った理論だそうなので、できなくて当然。
そんなこと言われても、ああそうですかとしか。
最終的に得たのが次の式で、Dを拡散係数と呼ぶ。
元の講義ノートから変数の文字を変えたりして結局見にくくなった感が。。。
まぁこれを書いてわかった気になるのがひとつの目的なので。
tacobell さん

-
nice! 2
記事 52
テーマ パソコン・インターネット
プロフィール
ブログを紹介する


